Bart WalkThrough
A journey through the forward pass


- Seq2Seq Pretraining
- Big Idea: Bidirectional Encoder, Left-To-Right Decoder
- Demo of transformers.BartForConditionalGeneration
- Incremental Decoding
- Footnotes
Seq2Seq Pretraining
In October 2019, teams from Microsoft, Google and Facebook independently published three new transformer papers: UniLM, T5 and Bart. All three papers analyze found, in general that they achieve better downstream performance if they (a) replace Bert's bidirectional architecture with a seq2seq architecture and (b) Bert's fill-in-the blank cloze task with a more complicated mix of pretraining tasks. It's a fun game to try to match which of the following quotes from the abstract map to which paper:
-
While many modern approaches to transfer learning for NLP use a Transformer architecture consisting of only a single “stack” (e.g. for language modeling [GPT2] or classification and span prediction [BERT]), we found that using a standard encoder-decoder structure achieved good results on both generative and classification tasks.
-
The model is pre-trained using three types of language modeling tasks: unidirectional, bidirectional, and sequence-to-sequence prediction.
-
We present a denoising autoencoder for pretraining sequence to sequence models, ... it uses a standard Transformer-based neural machine translation architecture.
Answers: [^1] [^1]: Answers: (T5, Oct 24) , (UniLM, Oct. 15) , (Bart, Oct. 29)
If you got that right you are very lucky indeed!
Now lets dig a bit deeper on this big Seq2Seq idea, then dive into some interesting parts of the code!
Big Idea: Bidirectional Encoder, Left-To-Right Decoder
Bert is pretrained to try to predict mask tokens, and uses the whole sequence to get enough info to make a good guess. This is good for tasks where the prediction at position i can depend on information from positions after i, but suboptimal for tasks where you are not, like text generation, where you generate the next word conditional on the words you have seen BEFORE.
In the code, bert's "Fully Visible" attention_mask is boring:
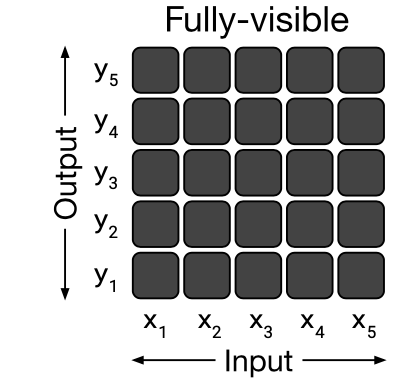
GPT2, meanwhile, is pretrained to predict the next word. This makes it good at generation tasks, where there aren't future tokens to consider, but suboptimal for other downstream tasks where the causal mask provides no benefit.
Here is the attention mask for GPT2, white squares in y2, x3 show that the prediction for timestep 2 does not depend on the input at timestep 3.
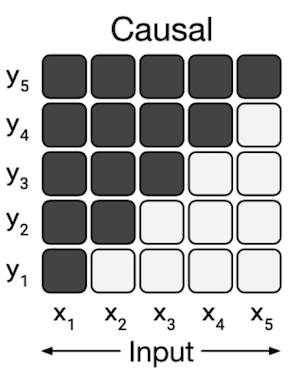
Our new friends get the best of both worlds:
The encoder is bidirectional - each token's attention can attend to every other token in the input sequence, while the decoder, which will ultimately have to perform generation, is causal like GPT2.
We can think about this attention pattern as smushing together our previous two attention masks, or "Causal Mask with a fully visible prefix" in fancier terms.1
The indices dont line up perfectly for the smush to work, but tokens 1 and 2 are the fully visible prefix (or the input to the encoder) and tokens 3,4,5 are the causally masked suffix (or inputs to the decoder). In summarization terms, you could imagine tokens 1 and 2 as the article, and we generate tokens 3-5 auto-regressively.↩
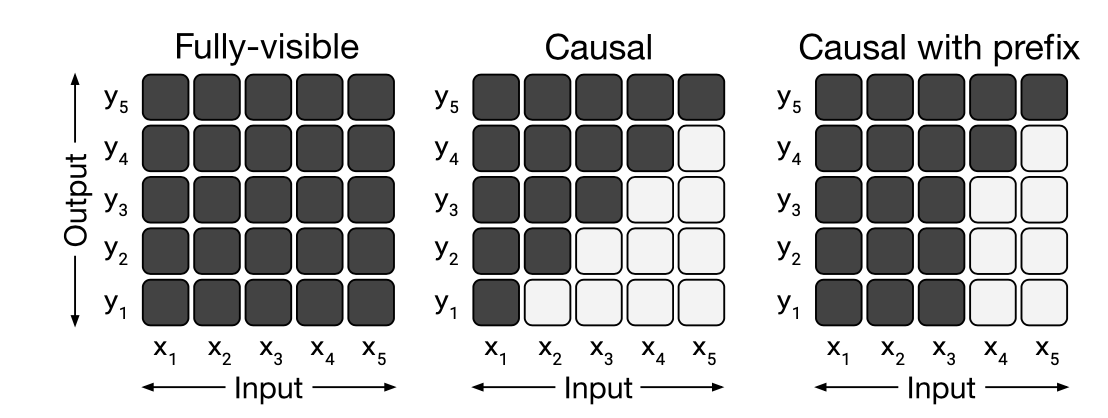
This attention pattern is very well suited to summarization and other conditional generation tasks. You are allowed to attend to the whole document, but as you write your summary, one word at a time, you need only consider what you've already written. The numbers confirm this: all the new fancy guys do a lot better than the old less-fancy guys.
#collapse-hide
import pandas as pd
pd.read_csv('tab1.csv', index_col=0)
BertSumABS [^2] , exploits the Seq2Seq architecture but doesn't pretrain the decoder.
Also note that t5-11b is 22x bigger than Bart), and pretraining objectives.
Bart tries out crazy pretraining tasks that you can only do with a seq2seq architecture. Since "Inputs to the encoder need not be aligned with decoder outputs, allowing arbitary noise transformations." They invent a pretraining task called Text Infilling, where you replace a span of text with a single mask token. This span can be of any length, so the model also must learn how many tokens to generate.
There is also another trick in Bart: each decoder layer performs cross-attention over the final hidden state of the encoder output. This presumably nudges Bart towards generating summaries that are closely connected to the original (encoded) text.
imports
#collapse-hide
import torch
torch_device = 'cuda' if torch.cuda.is_available() else 'cpu'
LONG_ARTICLE = ' (CNN)The Palestinian Authority officially became the 123rd member of the International Criminal Court on Wednesday, a step that gives the court jurisdiction over alleged crimes in Palestinian territories. The formal accession was marked with a ceremony at The Hague, in the Netherlands, where the court is based. The Palestinians signed the ICC\'s founding Rome Statute in January, when they also accepted its jurisdiction over alleged crimes committed "in the occupied Palestinian territory, including East Jerusalem, since June 13, 2014." Later that month, the ICC opened a preliminary examination into the situation in Palestinian territories, paving the way for possible war crimes investigations against Israelis. As members of the court, Palestinians may be subject to counter-charges as well. Israel and the United States, neither of which is an ICC member, opposed the Palestinians\' efforts to join the body. But Palestinian Foreign Minister Riad al-Malki, speaking at Wednesday\'s ceremony, said it was a move toward greater justice. "As Palestine formally becomes a State Party to the Rome Statute today, the world is also a step closer to ending a long era of impunity and injustice," he said, according to an ICC news release. "Indeed, today brings us closer to our shared goals of justice and peace." Judge Kuniko Ozaki, a vice president of the ICC, said acceding to the treaty was just the first step for the Palestinians. "As the Rome Statute today enters into force for the State of Palestine, Palestine acquires all the rights as well as responsibilities that come with being a State Party to the Statute. These are substantive commitments, which cannot be taken lightly," she said. Rights group Human Rights Watch welcomed the development. "Governments seeking to penalize Palestine for joining the ICC should immediately end their pressure, and countries that support universal acceptance of the court\'s treaty should speak out to welcome its membership," said Balkees Jarrah, international justice counsel for the group. "What\'s objectionable is the attempts to undermine international justice, not Palestine\'s decision to join a treaty to which over 100 countries around the world are members." In January, when the preliminary ICC examination was opened, Israeli Prime Minister Benjamin Netanyahu described it as an outrage, saying the court was overstepping its boundaries. The United States also said it "strongly" disagreed with the court\'s decision. "As we have said repeatedly, we do not believe that Palestine is a state and therefore we do not believe that it is eligible to join the ICC," the State Department said in a statement. It urged the warring sides to resolve their differences through direct negotiations. "We will continue to oppose actions against Israel at the ICC as counterproductive to the cause of peace," it said. But the ICC begs to differ with the definition of a state for its purposes and refers to the territories as "Palestine." While a preliminary examination is not a formal investigation, it allows the court to review evidence and determine whether to investigate suspects on both sides. Prosecutor Fatou Bensouda said her office would "conduct its analysis in full independence and impartiality." The war between Israel and Hamas militants in Gaza last summer left more than 2,000 people dead. The inquiry will include alleged war crimes committed since June. The International Criminal Court was set up in 2002 to prosecute genocide, crimes against humanity and war crimes. CNN\'s Vasco Cotovio, Kareem Khadder and Faith Karimi contributed to this report.'
LONG_ARTICLE
tokenizer = BartTokenizer.from_pretrained('bart-large-cnn')
article_input_ids = tokenizer.batch_encode_plus([LONG_ARTICLE], return_tensors='pt')['input_ids'].to(torch_device)
model = BartForConditionalGeneration.from_pretrained('bart-large-cnn')
summary_ids = model.generate(article_input_ids, num_beams=4, length_penalty=2.0,
max_length=140, min_len=55)
tokenizer.decode(summary_ids.squeeze(), )
TODO(SS): output of above gets smushed into one line it is really
The Palestinian Authority becomes the 123rd member of the International Criminal Court. The move gives the court jurisdiction over alleged crimes in Palestinian territories. Israel and the United States opposed the Palestinians' efforts to join the body. But Palestinian Foreign Minister Riad al-Malki said it was a move toward greater justice.
TODO: get conditional generation working on GPT2 for this Doc. The following code just generates eos.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
gpt2_tok = GPT2Tokenizer.from_pretrained('gpt2')
gpt2_model = GPT2LMHeadModel.from_pretrained('gpt2')
article_input_ids = gpt2_tok.batch_encode_plus([LONG_ARTICLE], return_tensors='pt', pad_to_max_length=False)['input_ids'].to(torch_device)
summary_ids = gpt2_model.generate(article_input_ids, max_length=article_input_ids.shape[1] + 155, do_sample=False)
gpt2_tok.decode(summary_ids.squeeze(), ).split('\n')
One thing to notice in these two snippets: even though BartForConditionalGeneration is a seq2seq model, and GPT2LMHeadModel is not, they can invoked in similar ways for generation.
BartForSequenceClassification and all the other *ForSequenceClassification in transformers.
Even though you can just pass input_ids, like the other models, BartModel (and all it's children)'s full signature is a little more complex:
def forward(
self,
input_ids,
attention_mask=None, # ignored pad tokens in input_ids
decoder_input_ids=None, # make these if not supplied
decoder_padding_mask=None, # ignored pad tokens in decoder_input_ids
):
When we're doing summarization finetuning, or seq2seq pretraining, we need to pass decoder_input_ids. (the masks will be made for you if you dont supply them).
When we're not, like in a classification context, you can safely ignore all the decoder kwargs and BartModel will make them for you by taking the input_ids (movie review) and shifting them to the right. Random, I know.
The authors' motivation for the shift-right trick was to facilitate teacher forcing during pre-training, and now that the model has been trained on 64 TPUs for 12 weeks to process this input format, we continue the pattern during inference, but hide it inside the forward method.
When I first read the fairseq code, there was a function called make_generation_fast which didnt do much besides catch my eye. What an exciting name!
Anyways, here is a really slow (pseudocode) way to greedily generate summaries
output_tokens = []
while not done:
encoder_hidden_state = model.encoder(article_input_ids)
logits = model.decoder(encoder_hidden_state, output_tokens)
next_word = logits.argmax()
output_tokens.append(next_word)
if next_word == eos: break
We can just cache the first step and save half the compute
output_tokens = []
encoder_hidden_state = model.encoder(article_input_ids)
while not done:
logits = model.decoder(encoder_hidden_state, output_tokens)
next_word = logits.argmax()
output_tokens.append(next_word)
if next_word == eos: break
Easy peasy, sorry for wasting your time. Here comes the fun one
Partially caching k and v in DecoderLayer
Here is some pseudocode for attention without all the reshapes and heads and masks and scaling.
class SimplifiedAttention(nn.Module):
def __init__(self, embed_dim):
self.Wq = torch.nn.Linear(embed_dim, embed_dim)
self.Wk = torch.nn.Linear(embed_dim, embed_dim)
self.Wv = torch.nn.Linear(embed_dim, embed_dim)
self.dense = torch.nn.Linear(embed_dim, embed_dim)
def forward(self, query, key, value):
q = self.Wq(q)
k = self.Wk(k)
v = self.Wv(v)
matmul_qk = torch.matmul(q, k.T)
attention_weights = matmul_qk.softmax(dim=-1)
output = torch.matmul(attention_weights, v)
return self.dense(output)
Now lets glimpse at the callers inside bart's DecoderLayer:
(LayerNorms and dropouts deleted for simplicity). Here's some more pseudocode
class SimplifiedDecoderLayer(nn.Module):
def __init__(self, embed_dim):
self.self_attn = SimplifiedAttention(embed_dim)
self.encoder_attn = SimplifiedAttention(embed_dim)
def forward(x, last_encoder_hidden_state, *masks_etc):
# x shape `(batch_size, tokens_generated_so_far, embed_dim)`
# x comes from decoder
x = self.self_attn(query=x, key=x, value=x) # pay attention to somebody else for a change!
output = self.encoder_attn(
query=x,
key=last_encoder_hidden_state, # could be None
value=last_encoder_hidden_state,
)
return output
What did we learn?
- In
encoder_attention, we can cache everything that doesn't depend on q, namely these outputsk = self.Wk(k) v = self.Wv(v)
The more exciting optimization is that in self_attn, we can cache the part of k,v that depends on
x[:, :1] the tokens we've already generated. Then each time through the generation loop, we only pass in x[:, :-1] and apply concatenation:
k = torch.cat((past_key, new_k), dim='seq_len') # the seq_len dimension,
v = torch.cat((past_value, new_v), dim='seq_len')
TODO(SS): Why cant we cache part of q?
Of the 8 F.linear ops performed by each DecoderLayer was doing, we've managed to completely cache 2 of them, and almost completely cache 2 more. Overall, we chop off about 40% of the runtime. TODO(SS): verify.
Footnotes
[^2] "Text Summarization with Pretrained Encoders" https://arxiv.org/abs/1908.08345
[^3] Differences between the UniLM Masking strategy and Bart
Note Most of our other models do not make inputs for the user -- that's the tokenizer's job, but as the t5 authors write: > "A major factor that differentiates the architectures is the mask used by different attention mechanisms in the model."