Introducing BART
Episode 1 -- a mysterious new Seq2Seq model with state of the art summarization performance visits a popular open source library


- Overview
- Background: Seq2Seq Pretraining
- Summarization
- Demo: BartForConditionalGeneration
- Conclusion
Overview
For the past few weeks, I worked on integrating BART into transformers. This post covers the high-level differences between BART and its predecessors and how to use the new BartForConditionalGeneration to summarize documents. Leave a comment below if you have any questions!
Background: Seq2Seq Pretraining
In October 2019, teams from Google and Facebook published new transformer papers: T5 and BART. Both papers achieved better downstream performance on generation tasks, like abstractive summarization and dialogue, with two changes:
- add a causal decoder to BERT's bidirectional encoder architecture
- replace BERT's fill-in-the blank cloze task with a more complicated mix of pretraining tasks.
Now let's dig deeper into the big Seq2Seq pretraining idea!
Bert vs. GPT2
As the BART authors write,
(BART) can be seen as generalizing Bert (due to the bidirectional encoder) and GPT2 (with the left to right decoder).
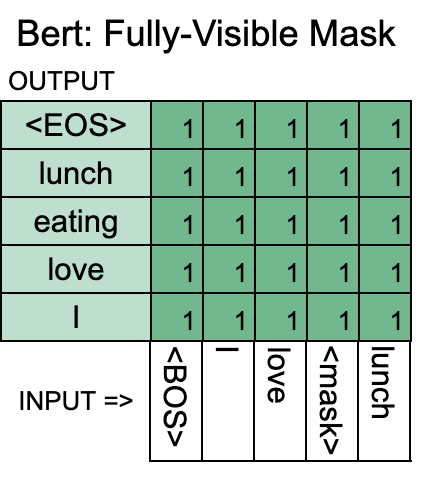
Bert is pretrained to try to predict masked tokens, and uses the whole sequence to get enough info to make a good guess. This is good for tasks where the prediction at position i is allowed to utilize information from positions after i, but less useful for tasks, like text generation, where the prediction for position i can only depend on previously generated words.
In code, the idea of "what information can be used use when predicting the token at position i" is controlled by an argument called attention_mask1. A value of 1 in the attention mask means that the model can use information for the column's word when predicting the row's word.
Here is Bert's "Fully-visible"2 attention_mask:
GPT2, meanwhile, is pretrained to predict the next word using a causal mask, and is more effective for generation tasks, but less effective on downstream tasks where the whole input yields information for the output.
Here is the attention_mask for GPT2:
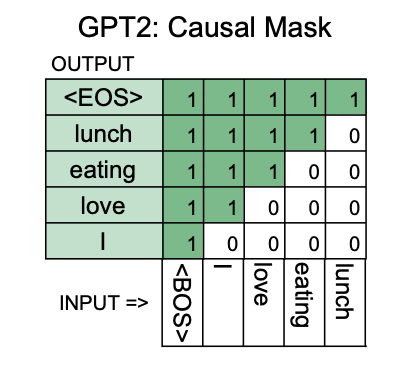
The prediction for "eating", only utilizes previous words: "<BOS> I love".
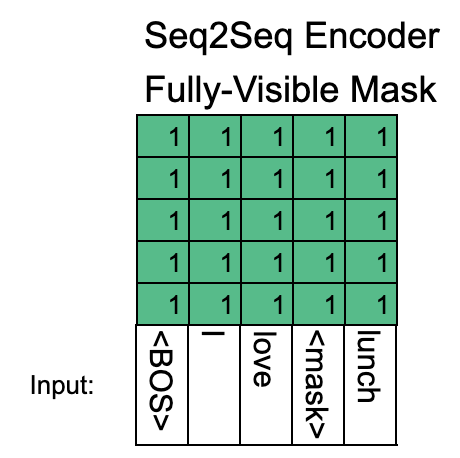
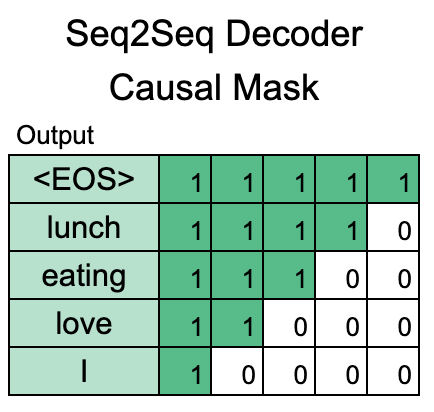
The encoder and decoder are connected by cross-attention, where each decoder layer performs attention over the final hidden state of the encoder output. This presumably nudges the models towards generating output that is closely connected to the original input.
Pretraining: Fill In the Span
Bart and T5 are both pretrained1 on tasks where spans of text are replaced by masked tokens. The model must learn to reconstruct the original document. Figure 1 from the BART paper explains it well:
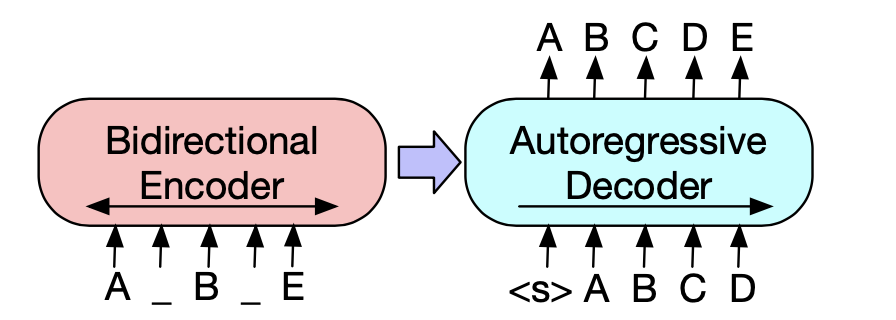 In this example, the original document is A B C D E. the span
In this example, the original document is A B C D E. the span [C, D] is masked before encoding and an extra mask is inserted before B, leaving the corrupted document 'A _ B _ E' as input to the encoder.
The decoder (autogressive means "uses a causal mask") must reconstruct the original document, using the encoder's output and previous uncorrupted tokens.
This is a bit of a simplification. Both papers experiment with many different pretraining tasks, and find that this one performs well. T5 uses a "replace corrupted spans" task. Instead of putting masks, they put in a random token.↩
In summarization tasks, the input sequence is the document we want to summarize, and the output sequence is a ground truth summary.
Seq2Seq archictectures can be directly finetuned on summarization tasks, without any new randomly initialized heads. The pretraining task is also a good match for the downstream task. In both settings, the input document must be copied from the input with modification. The numbers confirm this: all the new fancy Seq2Seq models do a lot better than the old less-fancy guys on the CNN/Daily Mail abstractive summarization task, and BART does especially well.
| Model | Rouge2 | Model Size | Pretraining |
|---|---|---|---|
| PT-Gen | 17.28 | 22 M | None |
| TransformerAbs | 17.76 | 200M | None |
| BertSumABS | 19.39 | 220 M | Encoder |
| UniLM | 20.3 | 340 M | Seq2Seq |
| T5-base | 20.34 | 770 M | Seq2Seq |
| Bart | 21.28 | 406 M | Seq2Seq |
| T5-11B | 21.55 | 11 B | Seq2Seq |
-
BertSumABS(from Text Summarization with Pretrained Encoders, uses a Seq2Seq architecture but doesn't pretrain the decoder.TransformerAbs, from the same paper, uses a slightly smaller model and no pretraining. -
PT-Genis from Get To The Point: Summarization with Pointer-Generator Networks - UniLM is a "Prefix-LM" with a similar masking strategy to Bart and T5.
#collapse-hide
INSTALL_MSG = """
Bart will be released through pip in v 3.0.0, until then use it by installing from source:
git clone git@github.com:huggingface/transformers.git
git checkout d6de6423
cd transformers
pip install -e ".[dev]"
"""
import torch
try:
import transformers
from transformers import BartTokenizer, BartForConditionalGeneration
except ImportError:
raise ImportError(INSTALL_MSG)
from IPython.display import display, Markdown
torch_device = 'cuda' if torch.cuda.is_available() else 'cpu'
LONG_BORING_TENNIS_ARTICLE = """
Andy Murray came close to giving himself some extra preparation time for his w
edding next week before ensuring that he still has unfinished tennis business to
attend to. The world No 4 is into the semi-finals of the Miami Open, but not be
fore getting a scare from 21 year-old Austrian Dominic Thiem, who pushed him to
4-4 in the second set before going down 3-6 6-4, 6-1 in an hour and three quarte
rs. Murray was awaiting the winner from the last eight match between Tomas Berdy
ch and Argentina's Juan Monaco. Prior to this tournament Thiem lost in the secon
d round of a Challenger event to soon-to-be new Brit Aljaz Bedene. Andy Murray p
umps his first after defeating Dominic Thiem to reach the Miami Open semi finals
. Muray throws his sweatband into the crowd after completing a 3-6, 6-4, 6-1 vi
ctory in Florida . Murray shakes hands with Thiem who he described as a 'strong
guy' after the game . And Murray has a fairly simple message for any of his fell
ow British tennis players who might be agitated about his imminent arrival into
the home ranks: don't complain. Instead the British No 1 believes his colleagues
should use the assimilation of the world number 83, originally from Slovenia, a
s motivation to better themselves. At present any grumbles are happening in priv
ate, and Bedene's present ineligibility for the Davis Cup team has made it less
of an issue, although that could change if his appeal to play is allowed by the
International Tennis Federation. Murray thinks anyone questioning the move, now
it has become official, would be better working on getting their ranking closer
to his. 'If he was 500 in the world they wouldn't be that fussed about it but ob
viously he threatens their position a bit,' said the 27 year-old Scot. ' and he'
s obviously the British number two, comfortably. 'So they can complain but the b
est thing to do is use it in the right way and accept it for what it is, and try
to use it as motivation whether they agree with it or not. He's British now so
they've just got to deal with it. Murray stretches for a return after starting h
is quarter final match slowly on the show court . Thiem held nothing back as he
raced through the opening set, winning it 6-3 with a single break . The young Au
strian is considered to be one of the hottest prospects on the ATP Tour . 'I wou
ld hope that all the guys who are below him now like James (Ward) , Kyle (Edmund
) , Liam (Broady) they will use it as motivation. If he becomes eligible for Dav
is Cup then those guys are going to have to prove themselves. 'It can only be se
en as a positive for those guys using it to try to get better. He's a good playe
r but so are James and Kyle and Liam has improved. Aljaz is there, he's on the t
our every week, the other guys aren't quite there yet.' For the first time Murra
y, who has an encyclopaedic knowledge of the top 100, gave his opinion of Bedene
: 'He's a good player with a very good serve. He's a legitimate top 100 player,
when he plays Challengers he's there or thereabouts, when he plays on the main t
our he wins matches, it's not like he turns up and always loses in the first rou
nd. Murray's fiancee was once again watching from the stands shaded by a huge br
immed hat . Kim Sears flashes her enormous diamond engagement ring while watchin
g her beau on court . 'He had a bad injury last year (wrist) but has recovered w
ell. I would imagine he would keep moving up the rankings although I don't know
exactly how high he can go. I've practised with him a couple of times, I haven't
seen him play loads, but when you serve as well as he does it helps. I would im
agine he' s going to be comfortably in the top 70 or 80 in the world for a while
.' It is understood the Lawn Tennis Association will give background support to
his case regarding the Davis Cup but have made it clear that the onus is on him
to lead the way. An official statement said: 'To have another player in the men'
s top 100 is clearly a positive thing for British tennis and so we very much wel
come Aljaz's change in citizenship.' The last comparable switch came twenty year
s ago when Greg Rusedski arrived from Canada. It was by no means universally pop
ular but, like Bedene, he pledged that he was in for the long haul and, in fairn
ess to him, he proved true to his word. Loising the first set shocked Murray int
o life as he raced to a commanding lead in the second . The No 3 seed sent over
a few glaring looks towards his team before winning the second set . Murray had
to put such matters aside as he tackled the unusually talented Thiem, a delight
to watch. Coached by Boris Becker's veteran mentor Gunter Bresnik, he slightly r
esembles Andy Roddick and hits with similar power but more elegance. His single
handed backhand is a thing of rare beauty. However, he has had a mediocre season
coming into this event and there was little to forewarn of his glorious shotmak
ing that seemed to catch Murray unawares early on. The world No 4 looked to have
worked him out in the second, but then suffered one of his periopdic mental lap
ses and let him back in from 4-1 before closing it out with a break. After break
ing him for 3-1 in the decider the Austrian whirlwind burnt itself out. 'He's a
strong guy who hits the ball hard and it became a very physical match,' said Mur
ray. Murray was presented with a celebratory cake after winning his 500th match
in the previous round .
""".replace('\n','')
#collapse-show
tokenizer = BartTokenizer.from_pretrained('bart-large-cnn')
model = BartForConditionalGeneration.from_pretrained('bart-large-cnn')
article_input_ids = tokenizer.batch_encode_plus([LONG_BORING_TENNIS_ARTICLE], return_tensors='pt', max_length=1024)['input_ids'].to(torch_device)
summary_ids = model.generate(article_input_ids,
num_beams=4,
length_penalty=2.0,
max_length=142,
min_len=56,
no_repeat_ngram_size=3)
summary_txt = tokenizer.decode(summary_ids.squeeze(), skip_special_tokens=True)
display(Markdown('> **Summary: **'+summary_txt))
GPT2, which in fairness is not finetuned for summarization, cannot really continue the tennis article sensically.
#collapse-show
from transformers import GPT2LMHeadModel, GPT2Tokenizer
gpt2_tok = GPT2Tokenizer.from_pretrained('gpt2')
gpt2_model = GPT2LMHeadModel.from_pretrained('gpt2', output_past=True)
# truncate to 869 tokens so that we have space to generate another 155
enc = gpt2_tok.encode(LONG_BORING_TENNIS_ARTICLE, max_length=1024-155, return_tensors='pt')
# Generate another 155 tokens
source_and_summary_ids = gpt2_model.generate(enc, max_length=1024, do_sample=False)
# Only show the new ones
end_of_source = "An official statement said:"
_, summary_gpt2 = gpt2_tok.decode(source_and_summary_ids[0]).split(end_of_source)
display(Markdown('> **GPT2:** ' + summary_gpt2))
More importantly, these snippets show that even though BartForConditionalGeneration is a Seq2Seq model, while GPT2LMHeadModel is not, they can be invoked in similar ways for generation.
Conclusion
Our first release of BartModel prioritized moving quickly and keeping the code simple, but it's still a work in progress. I am currently working on making the implementation in transformers faster and more memory efficient, so stay tuned for episode 2!
A big thank you to Sasha Rush, Patrick von Platen, Thomas Wolf, Clement Delangue, Victor Sanh, Yacine Jernite, Harrison Chase and Colin Raffel for their feedback on earlier versions of this post, and to the BART authors for releasing their code and answering questions on GitHub.